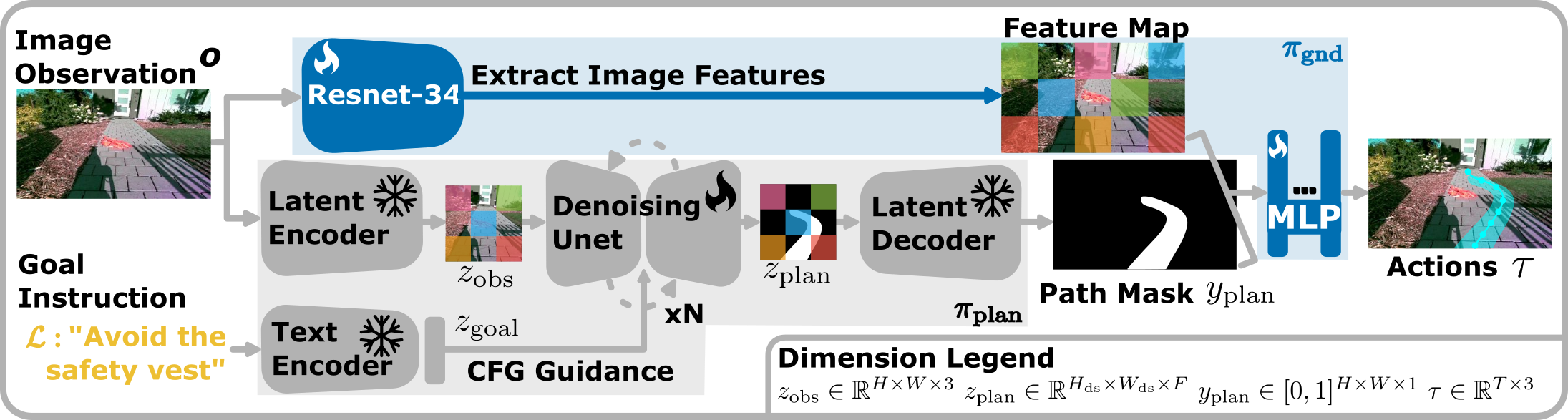
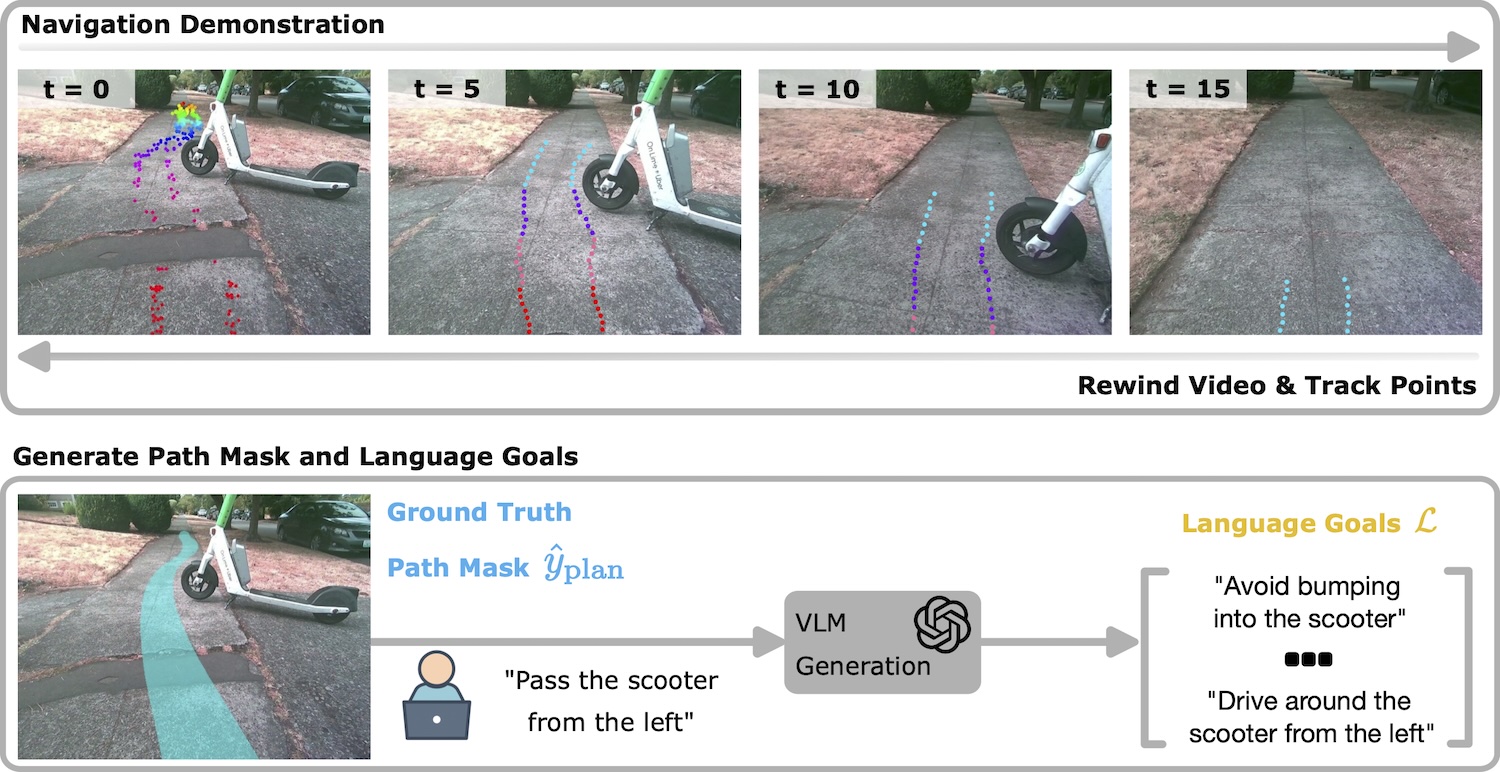
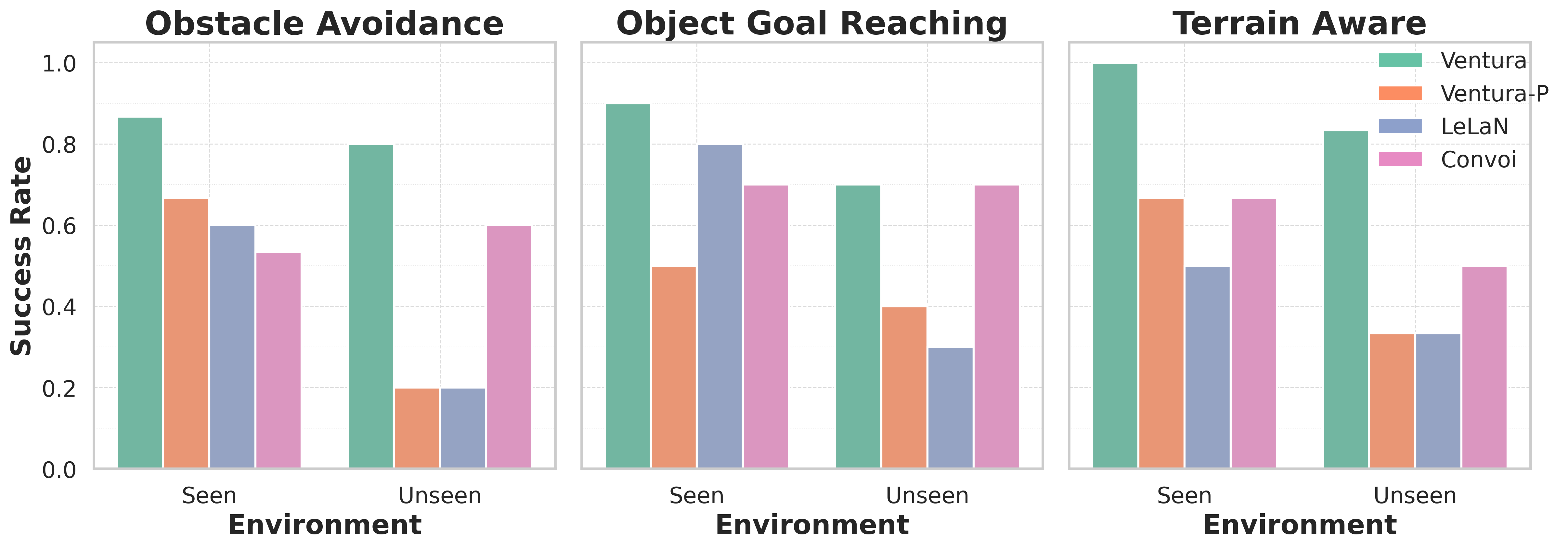
Adapting Image Diffusion Models for Visual Planning
VENTURA conditions on the image observation and goal instruction to denoise a path mask from random Gaussian noise.
A lightweight policy conditions on the predicted path mask and image features to produce a sequence of navigation waypoints.
In this manner, VENTURA leverages the strong priors of pre-trained diffusion models to produce precise, long-range navigation
plans that can be flexibly adapted to diverse tasks and environments.